An Intro to Resolving Duplicate Results in SQL Queries

I recently reviewed a SQL query that was returning duplicate results. Since I expected, and needed, a single result from the query this was a problem. Here’s an explanation of why this bug occurred, and several different ways it can be resolved.
My first attempt to remove the duplicates was to add the DISTINCT keyword to my query, but that didn’t fix the problem – I was still seeing duplicates. As I was looking at the result set more closely I realized that the problem was in how the query was structured and the columns that it was returning in the results.
I needed to return a lot of data in this query, and it included joins across several tables. Some of the tables that I was joining had one to many relationships with rows in other tables. That meant that when my result set was created, each of those many results got returned as its own unique row. For example, if I had one user joined to a table with four different category entries, the user would be returned in my result set four times, once for each category entry. Since that wasn’t the result that I wanted, I needed to think more carefully about what data I was returning in my select.
Suppose you have a database that lists a number of users, and jobs that they have had. There is a users table, a jobs table, and a user_jobs table that joins the two. Users can have had more than one job. Here is what the data looks like:

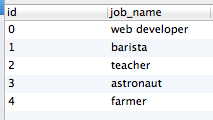

Let’s say you want to get a list of users, and also need some job data for those users. You only need a single job, not all the jobs. Here’s a sample query:

And here are the results:
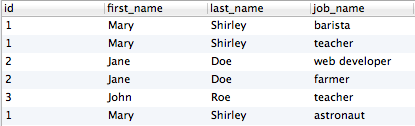
As you can see, there is some duplication in the results. We wanted to return a single record for each user, but instead we get multiple records for some users in the results. Looking across the result set, we can see that the “duplicate” results are not actually duplicates – the same user is being returned with multiple categories, making each row unique. So if we only want to return one of each user, how do we do it?
There are a few potential solutions for this:
One would be to structure your data differently, for example so that there was a one to one relationship with each category. This isn’t a good solution, as many cases, we’re dealing with data models that we didn’t create, that legacy code relies on, and that for whatever reason we can’t or don’t want to change. So, how can we to get unique user results within this data model?
Another potential solution is to break this up into multiple queries. Get the user list back first, then get a category associated with that user.
A third solution is to use a grouping within the initial query, to ensure that the data that is joined to the user data is also unique, thus a truly distinct data set is returned.

Now, we have a result set that only includes one of each user and some category data about that user.

As you can see, the data returned in a query set, and the joins you are making, needs to be carefully considered in order to return the correct results.
7 Comments