Differences in Model Validation and Saving in Rails and Ecto
Rails is a popular Ruby Web Application Framework
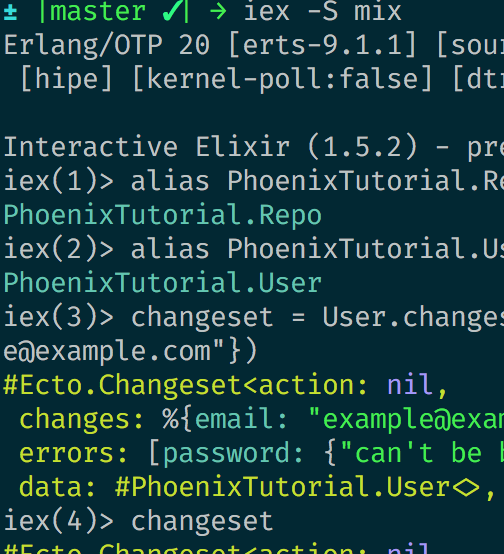
Ecto is a DSL (Domain Specific Language) for database adaptors in Elixir.
Rails is a popular Ruby Web Application Framework
Ecto is a DSL (Domain Specific Language) for database adaptors in Elixir.

In a previous blog post, I covered the “textbook” definition of continuous integration, along with a handful of tools and practices that fulfill or help to fulfill said definition. These tools and practices include breaking up your app into components (e.g. front-end and back-end, or, for much larger projects, using microservices), utilizing “watch” utilities locally to iteratively run tests, and choosing test-oriented frameworks (e.g. Rails, Django, Grails, etc.). However, I didn’t talk much about any specific continuous integration setup, nor some of the third-party services that go together to make an efficient release process. I also didn’t talk much about how continuous integration fits into the larger cycle of deployment and release management. I aim to cover some of those topics here, and fill in the larger picture of how CI helps to ensure code quality and stability in a software project.

As part of my exploration of a minimum set of devops tools, I’ve been learning how to stack containers full of Rails apps onto the Docker. There are plenty of examples of how to get started with Rails and Postgres on Docker, even one from the whale’s mouth, as it were. Working from this example, it was pretty clear to me that one of Docker’s major strengths is that it makes it really, really easy to get something running with a minimum of fuss; it took all of about a half day to learn enough Docker to hoist anchor, and even tweak a few things to my liking. One thing kept nagging me about the Docker example, though, and that was a warning from bundler when running docker-compose.

A common way to describe requirements on Agile projects is through the use of user story mapping, and, as a result, user stories. This post will not cover this process, but rather the process of taking an existing set of user stories and leveraging them within our development workflow to ensure that an application is built as accurately and efficiently as possible. To this effect, we will set up tools (Rails, RSpec, Capybara, FactoryGirl, and Guard, to be precise) for implementing our app using behavior-driven development. Structuring our app in this way gives us much better odds of producing robust, low-defect code that delivers on the requirements we set out to build.

Recently, I had the opportunity to work on an exciting in-house project for Grio called Filedart. This service, which will launch in the near future, affords the denizens of the web the ability to effortlessly upload content to the cloud by dragging photos or files to a small icon in their taskbar. After the file is uploaded by the client, the service automatically copies a mini-fied URL to the client’s clipboard. This URL leads to a brand-new, public web hosting wrapper for that file that they can easily distribute to their friends of colleagues to share. The service is free, and users don’t even have to log-in to use it.

Capistrano is an open source tool mainly used to deploy web applications from source code management (SCM) to one or more servers. The aim of this guide is showing how to easily deploy your app to amazon EC2 using Capistrano. We can leverage its multi-stage extension to provide a different deployment strategy in different scenarios.

One of the most raging debates within the web developer community is LAMP vs. Ruby on Rails (RoR), with countless posts all over the Internet that debate the merits of one versus the other… but this blog entry isn’t going to be one of them. You see, I’m new to RoR and hesitate to call myself an LAMP expert. So I’ll just discuss my own experience going from working on PHP-based sites to working on RoR-based sites.

In addition to outputting lots of useful information, the Rails logger can be a useful debugging tool. But debugging with the log file can become frustrating as it will be cluttered with default content. The solution to this problem is to create a custom logger and log file for such output.
The easiest way to do this is to create a global log function, enable it in your development environment, and make sure that calls to it don’t do anything in other environments.