SQL & NOSQL: A Brief History
The Relational Model & SQL
The relational model was proposed in a paper published in 1970 by Edgar Codd, a computer scientist working at IBM. In previous years, some storage systems had already emerged, but the relational model was first proposed with a strong theoretical basis.
In the relational model, data is archived in tables. Each table is composed of rows that contains multiple columns. It is possible to define constraints within the rows of a table (e.g. unicity constraints or external references). The relational model also provides a set of operations that can be used for data manipulation called Relational Algebra. In order maintain this operation, well-defined the rows within each table must have the same structure.
Some years after the publication of the Codd’s paper, IBM produced the first implementation of a relational database named SEQUEL that evolved into the current SQL (Structured Query Language) standard in the 1980’s. In fact, the first implementation the SQL language introduced some deviations from the original mathematical model but it rapidly became a standard. The basic idea was to provide a human readable language to perform the operations defined in relational algebra. With this purpose, SQL defines a specific syntax to construct text queries that can be directly executed on the database in order to insert, update, delete and select records.
Transactions and ACID properties
The first SQL implementations were not handling concurrency and were affected by data integrity issues. The behavior of the database was not predictable in situations in which two or more processes were accessing to the same data at the same time. Also, situations in which a query was just partially performed (for example due to a failure or constraint violation) were not handled and this produced “dirty” database statuses.
In the late 70’s Jim Gray proposed a transactional model for SQL in order to make it more reliable. A database transaction is a unit of work in which multiple queries can be performed in sequence.
The transactional model guarantee 4 properties usually referenced as ACID properties. The acronym is represented as follows:
- Atomicity: means that the execution of each transaction can be modeled as a single operations although it can contains multiple queries. If one of the queries in a transaction fails, the whole transaction is aborted leaving the database status unchanged.
- Consistency: the status of the database after each transaction should remain consistent. This means that the transaction execution should not violate any database constraints otherwise it will be aborted.
- Isolation: if multiple transactions are accessing to the same data at the same time, the resulting database status should be the same obtained executing the transactions in a serially (i.e.: one after the other). This means that the execution of a transaction should not interfere with the others.
- Durability: if a transaction is successfully committed, the system status should be persistent even in case of a system failure.
The CAP theorem and the BASE model
The SQL implementation has been widely discussed over the last 40 years. Although an SQL database guarantees a very reliable background for most applications, it also imposes some limitations:
- It can be hard to scale performance while maintaining the ACID properties
- The fact that archived data should have a predefined structure is a limit for some applications and introduces an overhead due to potential missing values
- The relational model was not envisioned to handle files (e.g.: images or videos), documents or large text fields
In the late 1990’s the growth of data handled by common applications demonstrated these limitations and grew the interest in distributed storage systems. The idea was to spread the data all over a network of interconnected nodes in order to distribute the system load evenly on multiple physical machines. This approach allows to use less powerful machines in order to contain costs. Also, it prevents single points of failure, provides easy scaling and can guarantee latency constraints.
The main issue in a distributed system is partitions. A partition occurs when a node in the network is not reachable by one or more of the other nodes (e.g.: the node crashes or the connection can not be established).
Partitions can not be avoided in a distributed network so a distributed storage system needs to ensure three main properties:
- Consistency: all nodes see the same data at the same time.
- Availability: every request received from the system produces a response that can be a result or a failure.
- Partition tolerance: if a partition occurs the system continues to work.
It is important to note that the definition of consistency in a distributed system is different from the definition of consistency in SQL database.
In 1998 Eric Brewer, a professor at UC Berkeley, proposed a conjecture proposing that these three properties can not be ensured at the same time. Some years later (2002) this conjecture was proven and today is known as the CAP Theorem or Brewer’s Theorem:
“Of three properties of shared-data system – Consistency, Availability, Partition Tolerance – only two can be achieved at any given time”
The CAP theorem does not means that the system can never provide these properties at the same time but it can guarantee just two of them. Also, as partitions cannot be avoided, it means that a distributed storage system can ensure Consistency and Availability, but not both.
Starting from this conjecture, Brewer proposed a new transaction model usually referenced with the BASE acronym (as opposite to ACID).
- Basically Available: the availability in terms of the CAP theorem is not insured. So a transaction could potentially not generate a response, but the system will try its best to do so.
- Soft state: the state of the system could change over the time even without any input.
- Eventually consistent: the system should become consistent over the time if it does not receive any input.
NOSQL database systems
The Brewer’s conjecture and its proof, caused a drastic decline of the interest in the distributed storage systems in the early 2000s. Some years later, with the growth of internet technologies, distributed storage systems regained popularity and appeared in a huge number of implementations.
One of the pioneers in this field was Google, who in the 2004 published a paper describing a distributed file system (Google File System or GFS) and a storage system built on top of it. This storage system, called BigTable, is modeled as a sparse multi-dimensional map distributed on multiple physical nodes. Some years later, inspired from the Google paper, Facebook implemented an internal storage system that became an open-source project named Cassandra, and the Apache Software Foundation implemented its own distributed file system, named Hadoop, and its own distributed storage system named HBase.
In the last 10 years other database models were also proposed (that are discussed later), and the number of implementations grew. All of these systems are generally indicated as NOSQL databases, but this acronym can be misleading because some of them support an SQL-like query language and also because they are not pointing out a specific model or implementation. Today there are more than 150 different database indicated as NOSQL but most of them can be grouped in 4 main categories: Key/Value Stores, Document Stores, Graph Databases, Wide Column Stores.
Key/Value Stores
Key/Value Stores are the simplest NOSQL database model. They can just store pairs of keys and values and retrieve a value for a given key. Due to the simplicity of the model, they can ensure very high performance. They can store a marshaled complex data structure as a value of a key, but the values are opaque to the system and can not be indexed. In some implementations, the keys are sorted and this allows range scans (e.g.: BerkeleyDB). Also, some implementations store the key/value pairs in-memory (e.g.: Redis, memCached) and this makes them very suitable for caching purposes.
Document Stores
Document stores are designed to handle semi-structured data (e.g.: XML or JSON). Usually they can store key/document pairs. The main difference with the key/value stores is that the documents are processed and their internal structures can be used for indexing and other optimization purposes. Unlike relational databases, a document store is schema-free so documents can have different structures and fields with the same name can have a different type in different documents. Also a document can contain nested structures like arrays or other documents. Due to their flexibility, document stores are commonly considered as the best alternative to SQL for web applications. Some of them, like MongoDB and CouchDB, also provide an SQL-like query language to perform complex queries.
Graph databases
In a graph database, data is represented as a graph in which each node is a record and each arc is a relationship between two nodes. They are optimized to represent complex data models (e.g. with a lot of foreign keys or many to many relationships) and offer good performance for data aggregations and graph-like queries. Some of them are implemented on distributed systems (e.g.: Titan) while other aren’t. Also, most of them can be accessed only using rest APIs (e.g.: Neo4j). This technology is still relatively new and not very widely used.
Wide Column Stores
Wide columns stores were inspired by the the Google Bigtable paper. The basic unit of data is a column (i.e. a name/value pair) that can be grouped in column families (roughly an SQL table) and super columns families as shown in the following image.

Each column can be independently accessed using a key. Columns with the same key form a row. In a wide column store each column is persisted in a different file in order to allow a better compression rates. These file are chunked and evenly distributed all over the network. Each value comes with a timestamp that allows versioning and can be used to solve eventual conflicts between different copies of the same value. Wide Column Stores provides very high performance and can be easily scaled. In fact, they are used by popular social networks like Twitter and Facebook to store content produced by their users.
Conclusions
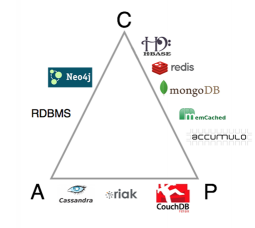
The following image shows how some of the most popular NOSQL databases are positioned in terms of the CAP Model. Each corner represent one of the CAP properties. If a database lies on an edge, it will ensure the pair of properties at the edge’s corners.

This table shows which model the databases in the previous figure are implementing.
| Key/Value Stores | Document Stores | Graph database | Wide Column Stores |
| Redis | MongoDB | Neo4j | Cassandra |
| memCached | CouchDB | Titan | HBase |
| riak | CouchBase | accumulo |
An interesting fact is that some of the databases shown in the figure are lying in a different edge although they are based on the same model (e.g: Cassandra and HBase or CouchDB and MongoDB). Another interesting fact is that Neo4j, although categorized as a NOSQL database, lies in the same edge as classical relational databases.
Furthermore, it is important to point out that some NOSQL databases, like Titan (graph database) or CouchBase (document store), can be configured in order to provide high availability or strong consistency in terms of the CAP theorem. Also, some NOSQL databases, like DynamoDB, OrientDB, MarkLogic etc., are based on hybrid models.
Finally, it’s important to note that the models discussed in this article are just the most popular today. Other interesting NOSQL models are Content Stores, used to store and index files like text, images, video, etc., Event Stores, used to persist changes in the status of objects, and RDF Stores, often used in semantic web to store RDF triples.
I hope this gives you some more background on the origins of SQL and NOSQL databases, and helps you choose the right solution for your next project!
2 Comments