Optimizing database queries
Most projects you will work on will have a database of some sort. For this reason, optimizing your queries allows you to use all that the database provides without having your application try to reinvent the wheel. In this blog, I’ll be using Postgres and Ruby on Rails to demonstrate some ways that you can optimize things. Much of the second section is Postgres specific, but the concepts should apply to whatever ORM you are using. Hopefully by the end you will have learned some new tricks to improve your project.
The first topic that I’m going to cover is Lazy vs Eager loading. Many ORM solutions default to lazy loading, however there are many cases where eagerly loading the relation data can produce significant time savings by reducing the number of queries that are made. Here is what the code looks like:
Lazy Loading
[code lang=Ruby]
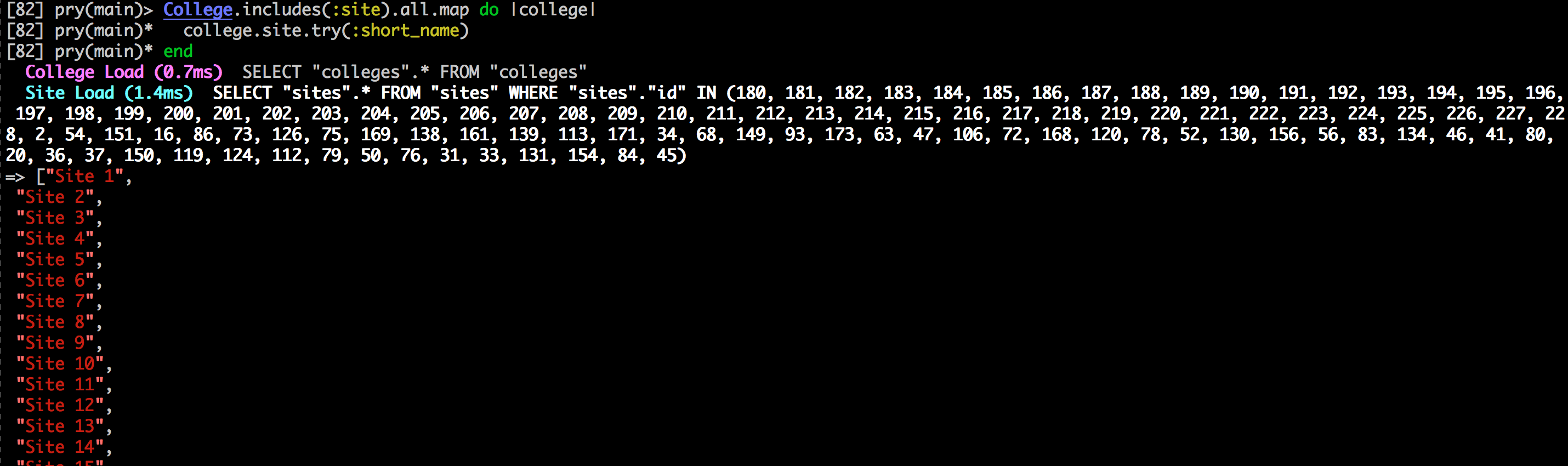
College.all.map do |college|
college.site.try(:short_name)
end
[/code]
Eager Loading
[code lang=Ruby]
College.includes(:site).all.map do |college|
college.site.try(:short_name)
end
[/code]
Clearly these examples look very similar, but now let’s look at the results of actually running the code:

Lazy loading queries

Eager loading queries
Note, the images are cropped due to space constraints. However, as you can see from the example, the lazy loading example has to making a large number of queries, while the eager loading example does everything in one! This this makes the eager loading example significantly faster in this case. As you may have noticed however, even though eager loading can produce significant savings, it isn’t the default behavior. You might ask, ‘why?’ The reason for that is that it also has a significant downside, in order to do everything in a single query it requires loading up all of the data into memory, so if you are constrained on memory or the query is sufficiently complex to the point that it has to load a very large amount of things into memory, you can run out of memory, causing problems. For this reason, as a developer, you need to be aware of of both the advantages and disadvantages of both eager and lazy loading. That way you can make the informed decisions and choose the option that works best for the use case of each of your queries.
This next section goes into using the databases to do calculations instead of trying to do them in your application with the returned results. The first db method we will discuss is rank. Using rank allows us to assign rankings to a portion of the data set based on criteria we define. Suppose we have a College record that we want to rank based on how many points it has. Here we can see a query that produces the same results, both using rank and without it:
Without rank
[code lang=Ruby]
College.joins(:college_points).order(`points desc`)
.where(college_points: { year: 2015})
.each_with_index.map do |college, index|
[college.short_name, index+1]
end
[/code]
Using rank
[code lang=Ruby]
College.joins(:college_points)
.where(college_points: { year: 2015})
.order(`points desc`)
.pluck(`colleges.short_name`,
`rank() over (order by points desc, short_name)`)
[/code]
In this case if two colleges have the same points, we will additional use the short_name field as a tiebreaker. Without using rank, we are forced to iterate over the results to calculate the rankings, while by using rank the database will calculate it for us. By letting the database work for us, we get a speed improvement.
The second db method we will discuss is array_agg. This will take all the results of a query and compress them into a single array as a result value. If you are familiar with the average function it works in a similar same way, except it results in an array instead of a singular value. Suppose from our prior example we want to find all the years that each College has a points value for, we can see an example of code that produces the same result with and without it here:
Without array_agg
[code lang=Ruby]
College.joins(:college_points)
.pluck(`colleges.id`,`college_points.year`)
.inject({}) do |results, row|
results[row[0]] = (results[row[0]].present?) ?
(results[row[0]] << row[1]).sort : [row[1]]
results
end.to_a.sort
[/code]
Using array_agg
[code lang=Ruby]
College.joins(:college_points).group(:id)
.pluck(`colleges.id`,
`array_agg(distinct college_points.year)`)
[/code]
It is worth noting, array_agg isn’t a very fast method, it will often be a bit slower than turning the results into an array ourselves after it is returned. However, what we give up in speed, we make up in readability of the code. As can been seen in the example, the code using array_agg is much more straightforward and clear as to what it is doing. In addition it also avoids having to iterate through the results that are returned from the query.
The third, and final, db method we will discuss is coalesce. This method effectively takes a number of values and will return the first one that isn’t a null value. As an example suppose we want a phone number for each user and a user has multiple phone numbers, some of which might be blank (null). Using coalesce, we can very easily get a number for each user that has any of them as well as set a preference order for people with multiple. As an example:
Without coalesce
[code lang=Ruby]
User.all.map do |user|
user.home_phone || user.cell_phone || user.work_phone
end
[/code]
Using coalesce
[code lang=Ruby]
User.pluck(`coalesce(home_phone, cell_phone, work_phone)`)
[/code]
Again, we gain readability by using the database method. In addition we also avoid iterating through the results.
If you notice, it all three examples of using db methods, we are able to remove the code iterating through the results set after the db produces it. This is a very good thing, because iteration like that is usually a red flag, since its time complexity in the best case is O(n) as it grows directly in relation to the size of the result set.
Since a database is almost always present in a project, improperly accessing and using it can results in poor app behavior. However, armed with knowledge about how to make it more efficient, you can also make the app faster overall!