Optimizing User Flow Test Automation with QA IDs
User flow testing, also known as workflow testing, analyzes how an application is performing from the standpoint of the user. In this post, I am going to talk about some of the challenges with automating these types of tests and how we’ve addressed these challenges on several recent projects.
What is User Flow Testing?
User flow testing analyzes what an application is presenting to a user. The goal is to use the application as the user would to identify any problem areas that they may encounter. The tests focus on three major areas:
- Elements: Are all of the elements visible on the screen?
- Navigation: Is the user able to navigate through the application as they’re supposed to be able to? Does the user get stuck anywhere?
- Functionality: Is the user able to perform all of the desired and required actions on the screen?
The Benefits of User Flow Testing
User flow testing is not the only testing performed on an application. When an application is initially developed, it goes through numerous checkpoints to ensure that the code is functional before it is deployed:
- Developer Testing: As developers design the application, they are continually performing tests to ensure the code is functioning properly.
- Unit Tests: As developers code they are also writing unit tests. These automated tests run every time a build is generated to confirm that the code being tested is still performing correctly.
- Code Reviews: Other developers review all pull requests to ensure that nothing is overlooked.
- Application Monitoring: In Production, the monitoring of applications focuses on areas of concern to ensure they are performing within defined parameters.
Here at Grio, we follow a mantra of “leave the code better than you found it.” Our employees take pride in their work, and everyone does a great job of taking ownership of their work before it is delivered to the client.
With all of these other testing steps in place, it begs the question: “why still perform user flow testing?”
User flow testing is separate from the other tests, in that it is the only test that is focused on the user’s point of view. Unlike other testing methods, user flow testing examines:
- Perspective: User flow tests seek to answer the questions: “Will the application make the user’s life easier or create more work for them? Is the software we are delivering a benefit or a burden?” Testing is focused on how the user experiences the application and allows the developers to see what they’ve implemented from the user’s perspective.
- Access: User flow testing gives developers the opportunity to ensure that all of the on-screen elements are accessible and that they perform as expected.
- Feature Focus: User flow testing tends to be specifically focused on features: how they are experienced by the user, and how they impact the user. The testing is therefore focused on determining if the user is able to navigate the application in an efficient way.
Automation Requires Identification
In order to automate user flow testing, we have to have a reliable way of identifying the elements that are on the screen and determining whether they have the correct attributes: Do they take the user to the correct location? Do they perform the expected functionality?
There are several different ways of identifying the on-screen elements. When choosing an identification method, the goal is to find one that is simple, scalable, and easy to maintain.
Once the identification method is chosen, we are able to run the automated test. However, this brings us to a key point: an automated test can fail. When an automated test fails, it can be a good failure or a bad failure.
For example, if we were comparing the text on the element to the text we expected to see, and it didn’t match because of a typo, an edit, or some other change, the test would fail and move on to the next step in the automated process. This is an example of a good test failure because the test fails on that section but continues working. In this failure, we simply have to update the text and rerun the test.
However, in a bad test failure, the maintenance to repair the failure is much more extensive. For example, if an element has been identified by its text but then that text is changed or edited, the identifier tool searching for that element with specific text won’t be able to find the element at all. In this scenario, the test concludes that the element doesn’t exist and therefore skips all subsequent steps in that module. This constitutes a bad failure because it shows an entire section failing, where several steps were never executed, instead of a single, specific, text failure.
When creating automated user flow tests, we work to minimize bad failures because when entire sections are skipped during testing, it renders the tests less effective and requires all tests related to the element that failed, as well as elements presented near it on the screen, to be updated before testing can be completed.
Therefore, the identification method we choose must minimize bad failures while also being compatible with the tool we are using.
The Pitfalls of Standard Identification Methods
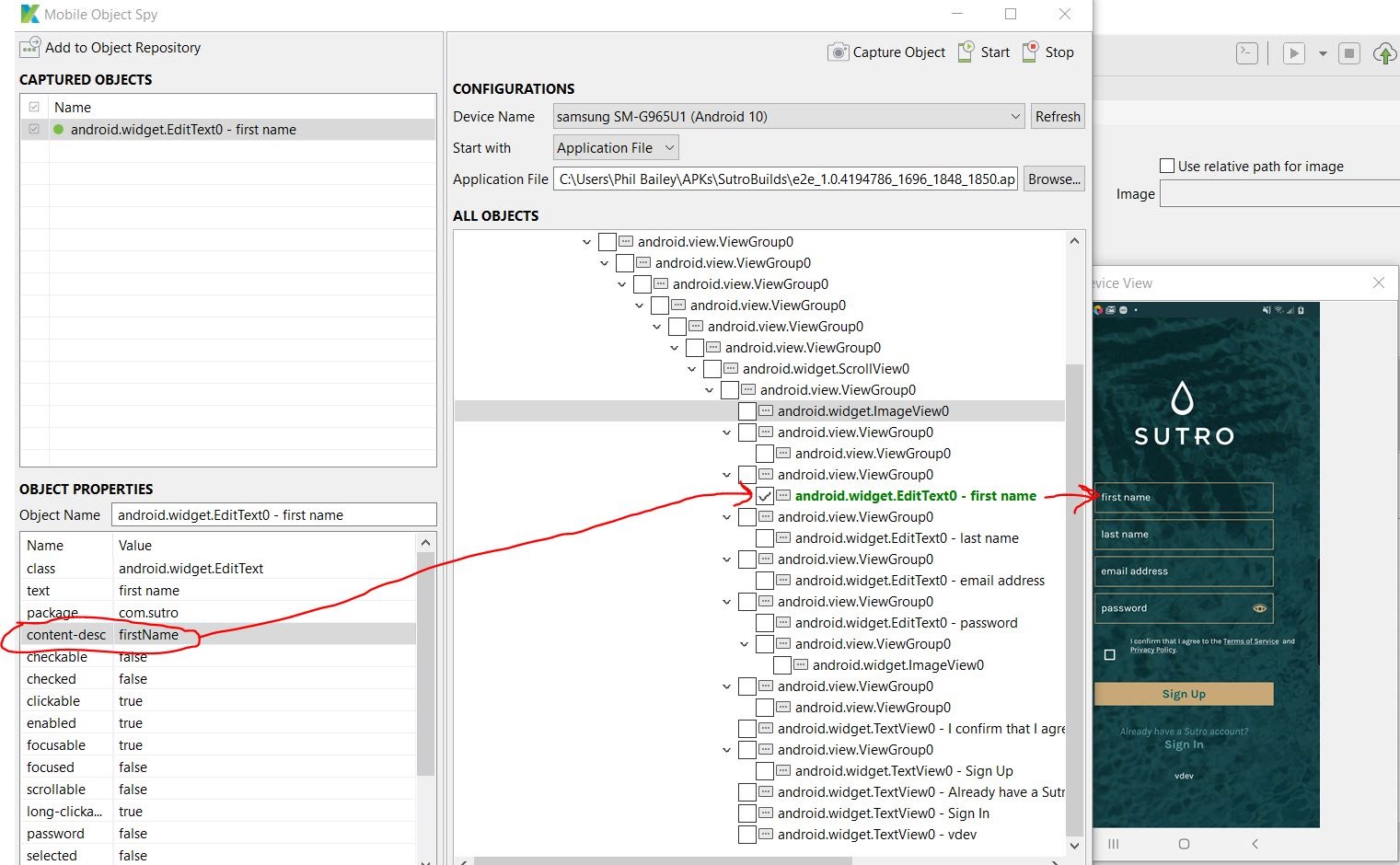
For my most recent project, I used an automation testing solution called Katalon Studio. To perform user flow tests, Katalon Studio uses an object spy to read each of the elements on an application. When the user selects an element, the spy is then able to show the user the interface where it thinks that the element is located and any attributes (such as text, links, etc.) that it can identify.
For example, let’s say we want to automate user flow testing for the “subscribe” button on a webpage. If we select the “subscribe” button, Katalon Studio gives us, the user, an overview of what it has identified.
In order to automate this process, we then have to select an identifier for the button that can be used during the test. Katalon Studio offers three standard options for identifiers:
Option 1: XPath (XML Path Language)
XPath identifies the location of the element within the XML. It works successfully by identifying both the element and the elements around it to give it a relative location. This identification is successful as long as nothing on the page ever moves. As soon as elements on the page change, the selected XML path value no longer matches, causing the test to fail because the element can not be found. Therefore, the XPath option is not an efficient solution for applications that undergo frequent changes.
Option 2: CSS
When we are using CSS elements, we run into the same challenges and problems that we faced with the XPath identifier. A single edit, including things as minute as a change in an element’s font, font weight, color, or location, can require a whole battery of tests to be rewritten before the test will function. Due to this fragility, CSS is no more efficient than the XPath option.
Option 3: Attribute Identifier
The attribute identifier option shows multiple identifiers that you can select. Although these attributes do work initially, just as in the case of the XPath and CSS options, when the selected values are changed, the test will determine that the element doesn’t exist and fail.
As you can see, the bad test failure as a result of moving elements is an inherent problem in the standard identification options. It’s an inconvenience that seems to apply to all of the standard tools.
The Solution: Unique Identification
With the number and frequency of changes that occur in our products, we needed to find an identifier that could remain relatively stable. We wanted a solution that worked on both web and mobile applications, and that was simple, scalable, and easy to maintain.
Fortunately, the developers at Grio had the solutions.
For the web version of our application, the solution was custom data attributes. Custom data attributes can be embedded into an HTML element without interfering with functionality. We created unique IDs for each element on the application using a data attribute (we called it the “data-philter” attribute).
The data-philter attribute allowed us to link each element with a unique ID that we could leverage over the long term to minimize test maintenance. Since the attribute doesn’t change when the page is updated, we were able to virtually eliminate bad test failures.
For the mobile version of the application, the solution was in accessibility tags. On Android, the accessibility tag is a piece of text that a user can use to receive an audible description of the screen. We discovered that accessibility tags could be given specific identifiers and, like the custom data attributes, they would remain stable when the application was updated.
To ensure that the accessibility tags were only altered during test builds, we made a repeatable build process that, when run, created an Android build that exposed the accessibility tags for the test framework to see. However, when the application was accessed with a production-facing build, the tags were not exposed.
By using the custom data attributes on web and the accessibility tags on mobile, we were able to implement an optimized solution to support user flow test automation and minimize test maintenance. Both solutions provided simple, scalable methods that can easily be applied to any current or future products.