Demystifying Regular Expressions
In this post, I am going to introduce one of the most contentious tools utilized by software developers: regular expressions. Regular expressions can be extremely useful, but they can also be complex and tedious at times. Many developers, therefore, have complex relationships with them.
According to Wikipedia, regular expressions are “a sequence of characters that specifies a search pattern. Usually such patterns are used by string-searching algorithms for ‘find’ or ‘find and replace’ operations on strings, or for input validation.” Just as you can use the “find” function to search for words in your Word document, developers can use regular expressions to find words, sequences, and patterns within their documents or code.
For example, say you have a long document that you wish to share, but you need to redact all of the email addresses and phone numbers of the participants before you send it out. If it is a long document, finding each individual telephone number and email address will be tedious, and the possibility of missing one will be high. However, with regular expressions, you can create commands that allow you to replace every telephone number or email address within the document with a simple click of a button.
In this post, I will introduce the various components of regular expressions, and explain how they can be combined to create complex search functions. For simplicity’s sake, this will all be in the context of a regex-enabled search box.
Regular Expression Components
To use regular expressions, it is important to understand the various components that you can utilize in your search function:
Boundaries
The boundaries of a regular expression are represented with dashes: /^Miguel.*$/. The boundaries of strings are represented by quotation marks: “Miguel.”
Starts and Ends
To search for the start of a string, you can use the ^ at the beginning of your search. To search for the end of a string, you can use $ at the beginning of your search. However, the end of the string is not always the end of a line. If you want the actual end of the line, you need to use \n in your search, as seen below.
 If you enter ^$ in the search bar, that indicates that you are searching for a start immediately followed by an end, so only empty lines will be matched.
If you enter ^$ in the search bar, that indicates that you are searching for a start immediately followed by an end, so only empty lines will be matched.
Any Character
Entering a . in the search bar indicates that you are searching for any single character. To search for one or more characters in a row, you can use .+. To search for zero or more characters, you can use .*.
Digits
To specify that you want to search for digits specifically, rather than all characters, you can use \d.
You can search for everything except digits by capitalizing the d: \D.
Alphanumeric Characters
If you want to search for alphanumeric characters rather than digits, you can search using \w, w is used as shorthand for “word characters”. Like the digits example above, to search for anything other than alphanumeric characters, you simply capitalize the w: \W.
Repetitions
If you want to search for repetition within the characters, you can use { } brackets. For example, if you enter .{10} in your search bar, it will give you any sets of 10 consecutive characters.
With the repetition brackets, you can also search for a range of characters. For example, if you search for \d{1,5}, you will be given any sets of consecutive digits that are 1-5 characters in length.
Letters
To search for letters, you can just do a simple text search, in which you enter the text you are searching for in your search box:

If you want to search for specific characters, you can use [ ] brackets. For example, searching [uis] will return any u, i, or s that is present in the document. Now, say you only want to find any location where two of these characters are found consecutively. Entering [uis]{2} will give you two consecutive u, i, or s’s in any order.
If you want to select any character that is not u, i, or s, you can use a caret within the square brackets like this: [^uis].
To select a range of characters, you can use a dash within your square brackets. For example, to search for any characters between a and g, you would enter [a-g]. This can also be combined with the repetition pattern to only search for repetitive numbers of characters a through g. For example, [a-g]{5} will give you any locations where the letters a through g occur concurrently at least five times.
Periods
To search for periods within the text, you’ll escape them by prepending a backwards slash, meaning \..
Optional
Say, for example, you want to search for Hilary in your document, but you are unsure if it is spelled “Hilary” or “Hillary.” The second “l” in the name becomes an optional character. To indicate the optional character, you can demarcate it with a ?. For example, searching Hill?ary will return any instances of Hilary or Hillary in the text.
If you are unsure what a character in your search would be, you can also make any character in that position an optional character in your search. For example, searching Hil.?ary will return “Hilary,” “Hillary,” “Hilaary,” etc.
White Spaces
To find the white spaces in your document, you can use \s. To find anything other than the white spaces, you can once again use capitalization: \S.
Capture Groups
Once you understand the various components of regular expressions, you can combine the rules above to define a specific group of characters to find or find and replace. Let’s once again look at the text example from above:

As an example, entering ^(/d+).*$ indicates that you want to find any row that begins with one or more digits followed by any number of characters. If you then indicate that you want to replace it with \1, any row that starts with a number will be replaced by the first consecutive number combination in that row, as seen in the image below:

As you can see above, the first row was not replaced because it does not start with a digit. Rows 2-9 were not replaced because they start with a space instead of a digit.
If you want to also replace rows 2-9, you can revise your find function to be ^\s(\d+).$. Adding the /s* at the beginning ensures that any row that begins with any number of spaces (including zero) will also be replaced, as seen below:

As you continue using regular expressions, they will continue to get longer and more complex.
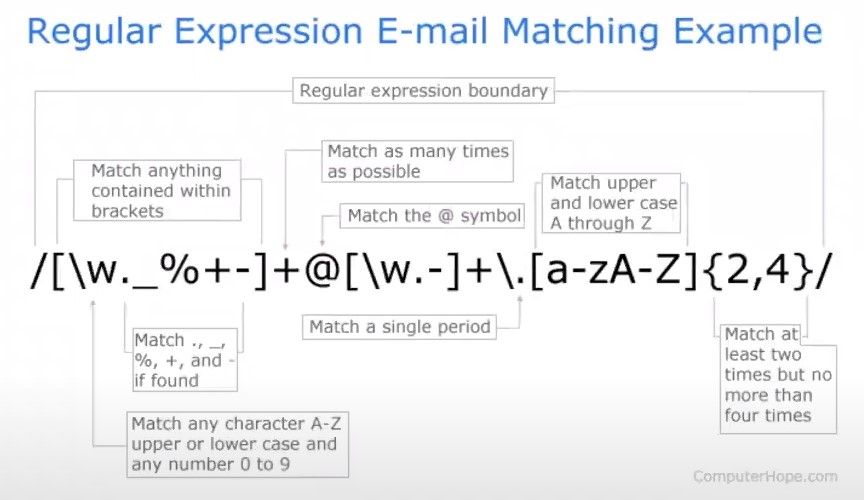
Let’s go back to our original example, in which we wanted to remove the email addresses from a document. This can be completed using the capture group /[\w._%+-]+@[\w.-]+.[a-zA-Z]{2,4}/.
The components of this regular expression are explained here:

While this is a longer regular expression than our other examples, it is nonetheless just a combination of the components discussed above.
Final Thoughts
Before you understand regular expressions, they can feel like magic. However, once you demystify them and begin to understand their mechanics, they can become an incredibly useful tool.